[파이썬 딥러닝_2] 사이킷런을 이용한 데이터학습(선형회귀)
오늘은 실제 데이터를 가지고 학습데이터를 만드는 방법을 알아보도록 하겟씁니다~
아마 케라스, 사이킷런은 어디선가 한번쯤은 들어보셨을겁네다.
우리는 사이킷런을 이용할건데요,
데이터를 가져오기에 앞서 사이킷런 웹페이지를 구경하면서
'어떤 데이터를 가지고 어떤 문제를 해결할 것'인지 정하여 봅시다.
scikit-learn: machine learning in Python — scikit-learn 1.2.2 documentation
scikit-learn: machine learning in Python — scikit-learn 1.2.2 documentation
Model selection Comparing, validating and choosing parameters and models. Applications: Improved accuracy via parameter tuning Algorithms: grid search, cross validation, metrics, and more...
scikit-learn.org
사이킷런 웹페이지로 들어와서 Examples를 눌러보면 다양한 릴리즈들이 나타나는데요.
여기서 마음에 드는 데이터를 골라봅니다.
영어만 잔뜩 써져서 찾기 힘드니까 검색차에 간단하게 datasets라고 검색해서 찾아봅시다.
알수없는(?) 목록들이 많지만 하단으로 쭉 내려보면 다음과 같이 파이썬 펑션으로 불러올 수 있는 데이터셋이 나타납니다.
우리가 배워온 데이터 정리는 나열된 값에 의한 것이니까 이번에도 나열된 값에 대한 것을 가져와봅시다.
마침 여기 유방암 자료가 있네요.

자 그럼 사이킷런부터 설치해봅시다.
파이참에서 > file > setting > +버튼 > scikit-learn > install package
헤메시는 분들 있을텐데 꼭 scikit-learn을 찾아서 설치해줍시다.
sklearn으로 설치하면 에러납니다 OTL 어떻게 아냐고요? 해봤거든요 ㅂㄷㅂㄷ...
설치가 끝났으면 아까 선택한 데이터셋을 눌러서 자세히 봅시다.
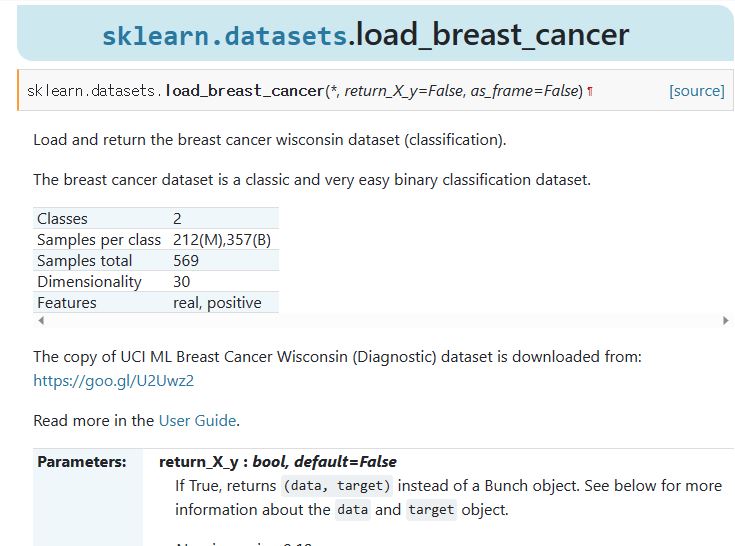
분석을 어케해야 좋을지 잘 모르겠지만 일단 내용을 읽어보면 어떻게 데이터를 정리할지 감이오게 되겠지요?
Class가 2개
Sample은 212(M), 357(B)개 합계 569개
Dimensionality는 특성이네요, 특성이 30개
Feature 피처는 리얼과 포지티브로 두가지네요.
=
데이터의 종류는 2개
샘플은 A와 B를 합하여 569개
특성은 30개
피처는 유/무 로 나타낼 수 있는 값이 두가지
대충 이렇게 이해하면 되겠지요.
1. 데이터 준비
첫번째로 데이터를 불러와봅니다.
source에 써있는것처럼 저 이름을 갖다쓰면 되갓지요?
from sklearn.datasets import load_breast_cancer
cancer = load_breast_cancer()
유방암 데이터셋을 cancer에 할당해줍니다.
이제부터 유방암 데이터셋을 불러오려면 cancer로 불러올 수 있겠죠?
두번째로 이 데이터의 크기가 웹페이지에 나타난 크기와 같은지 알아봅시다.
데이터셋은 뭔가를 하려면 항상 data와 target이 필요해요.
print(cancer.data.shape, cancer.target.shape)
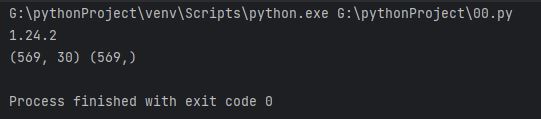
데이터셋을 쉽게 설명하자면
1엔 569*30으로 2차원으로 배열된 데이터가 있고(가로*세로)
2엔 569개 값이 일렬로 늘어진 데이터가 있는거에요(한줄짜리)
아까 위에서 데이터셋은 data와 target으로 만들어진다고 했었죠?
1 = data (569*30으로 2차원으로 배열된 데이터)
2 = target이 되는거죠! (569개 값이 일렬로 늘어진 데이터)
1. data 보기
이 data가 어떻게 나열되어있는지 조금 더 자세하게 보는 방법
print(cancer.data[0:5])
0부터 5까지 6개의 데이터를 슬라이싱해서 나타내면
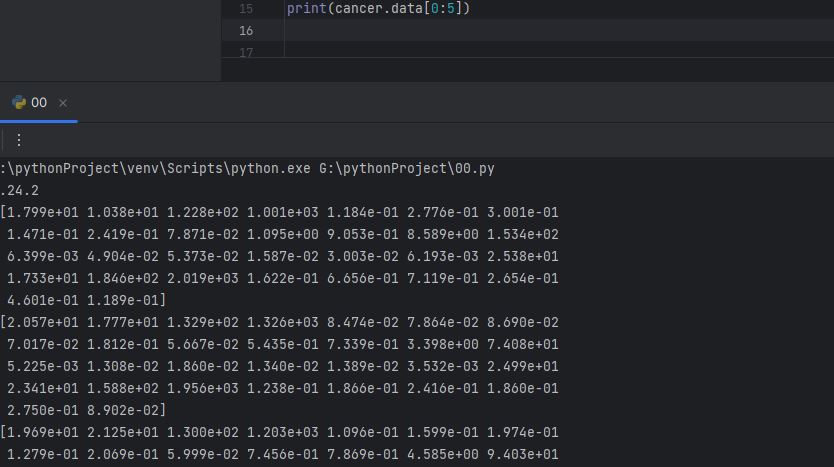
우리가 이런거 하나 몰라도 저거 한 줄의 값이 30개 인 걸 셀 수 있으니
저 한가지 값의 내부는 569라는 요소를 가진 무언가라는걸 유추할 수 있겠네요.
2. target 보기
이번엔 타겟데이터를 볼까요?
print(faces.target[0:5])

0부터 10까지 전부 0인 타겟데이터가 들어있네요.
이로서 우리는 data와 target에 어떤것들이 들어있는지 알아볼 수 있습니다.
2. 데이터 시각화
이 데이터들이 어떤 방식으로 들어있는지 산점도를 찍어봅시다.
저번 시간에 배웠던 맷플롯립을 이용할거에요.
맷플롯립이 기억이 안난다면?
나는 나는 지동킴, 지동킴의 티스토리 (tistory.com)
[파이썬 딥러닝_1] 넘파이&맷플롯립
파이썬 제대로 하지도 못하는데 딥러닝부터 파본다. 자 에디터가 있으신 분들은 에디터를 쓰시고 없으신 분들은 요기 밑에 구글 코랩을 쓰시면 됩니다. 오히려 초보자 접근성은 코랩이 더 좋아
jidongkim.tistory.com
import matplotlib.pyplot as plt
plt.scatter(cancer.data[:,2], cancer.target)
plt.xlabel('x')
plt.ylabel('y')
plt.show()

자 모아니면 도인 산점도가 나왔습니다ㅋㅋㅋㅋㅋ
아까 feature에 써있던것처럼 '이건 암임' 또는 '이건 암아님' 이런 느낌의 데이터로 보이네요
3. 훈련데이터 만들기
그럼 이제 이 데이터로 훈련데이터를 만들어봅시다.
x = cancer.data[:,5]
y = cancer.target
x에는 data를 y에는 target을 노나줬습니다. 0부터 5까지 훈련데이터로 써볼거에요.
data는 2차원 배열이니까 ' , ' 를 꼭 잘 써줍시다. 오류나요.
자 여기서부터 조끔 머리 아픈걸 알려드려야 하는데
우리가 지금까지 data와 target을 나타내는 방법을 보면 뭐가 생각나죠?
네 1차 함수죠.
y = ax + b
내가 찾고자 하는 값은 x와 b로 만든거죠.
우리는 지금까지 x는 data, b는 target으로 피겨를 그렸습니다.
우리는 이것을 선형회귀라고 합니다.
선형회귀 = 기울기와 절편을 찾기!
딥러닝 분야에서는 이 식을 다음처럼 쓰는데요
yˆ = wx + b
걍 생긴 거만 다르지 똑같은거라고 생각하면 됩니다.
w는 가중치, b는 절편이라고 부르는데요,
이 두가지는 알고리즘이 찾은 규칙이고 y햇은 예측값이라고 부릅니다요.
data = x = w(가중치)
target = b = b(절편)
=
data = x = w(가중치) = 기울기
target = b = b(절편) = 절편
이렇게 이해하시면 되갓습네다.
1. 가중치와 절편 초기화 하기
이 식을 훈련데이터에 적용할겁니다.
그러기 위해서 이 두가지를 초기화 할거에요.
w = 1.0
b = 1.0
w와 b에 1.0을 각각 할당해줍시다.
이 두가지를 1.0으로 초기화시킨거에요
2. 훈련데이터 만들기
다음으로 우리가 아는 식을 이용해서 이 훈련데이터의 y햇, 결과값을 알아봅시다.
y_hat = x[0] * w + b
print(y_hat)
y햇 = xw + b의 식이지요?
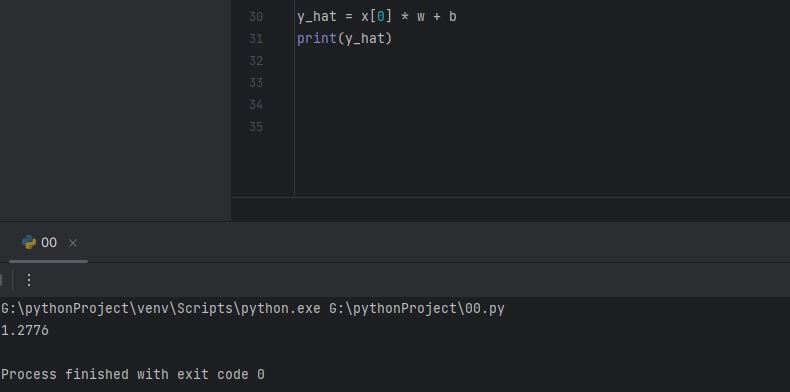
1.2776이라는 값이 나왔습니다.
3. 실제 데이터값과 비교하기
이제 이 값을 데이터의 실제 target값이랑 맞춰서 한번봅시다.
방금 만든 식은 우리가 만든 훈련데이터의 0번이었잖아요? 이번에는 실제 데이터셋의 0번이랑 비교해보는겁니다.
print(y[0])
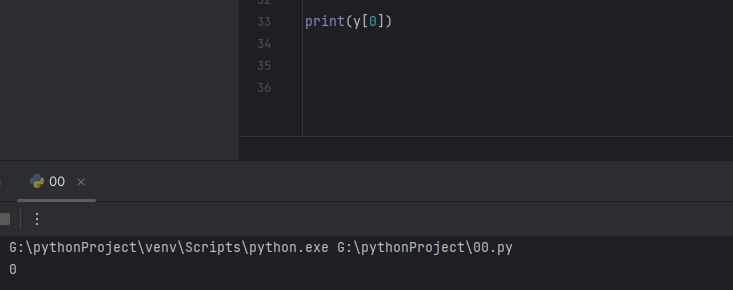
0이네요
사실 당연하죠 아까 우리가 target값 알아볼때 10까지 0이었고 피겨에서도 모아니면 도로 나왔으니까요.
근데 이러면 우리가 훈련데이터에 집어넣은거하고 실제 데이터하고 차이가 나는 거잖아요?
훈련데이터는 1.2776이 결과값인데 실제데이터는 0이니까요.
= 그렇다면 아까 처음에 설정한 초기화값을 조정해야된다!
4. 예측값찾기
무식하게 가봅시다 원래 처음엔 일단해보고 안되면 인터넷 뒤지고 어따가 물어보고 그러는거에요
내 생각엔 그게 프로그래밍의 본질이 아닐까 OTL
w_re = w + 0.1
y_hat_re = x[0] * w_re + b
print(y_hat_re)
w에 0.1을 더해서 y햇의 값을 바꾸는, re라고 덧붙인 식을 하나 만들었습니다.
w_re
y_hat_re
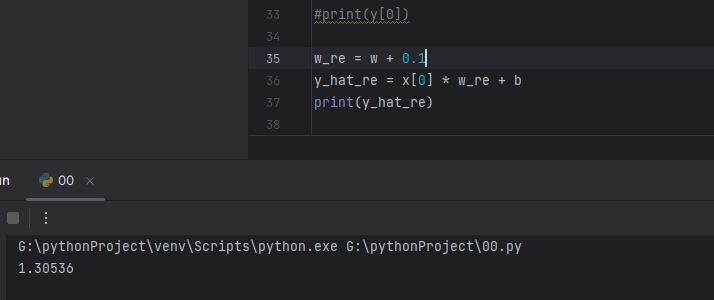
이런 시밤탱! 값이 더 벌어졌습니다.
그럼 뭐다? 이녀석은 음의 수로 더해가야 실제데이터와 비슷해진다 이말이다~
5. 증가값 찾기
아오 근데 우리가 언제까지고 계속 w에 얼마를 더해서 찾을수는 없잖아요?
w가 이만큼 증가하면 y햇이 얼마나 증가를 하는지 알면? 더 찾기쉽겠죠
w_jungga = (y_hat_re - y_hat) / (w_re - w)
print(w_jungga)
아~ 알아보기 쉬우면 장땡임~
증가한 값은 = y햇다시돌린값 - 원래값 / w다시돌린값 - 원래값

0.1이 늘어나면 결과값이 0.2775가 늘어나네요.
양의 수로 더해서 찾으려면 y햇의 값이 증가하면 되고
음의 수로 더해서 찾으려면 w의 값이 증가하면 됩니다.
우리는 음의 수로 더해야하니까 w를 조정하면 되겠네요
1. w를 조정하여 증가값 찾기
w_gamso = w + w_re
print(w_gamso)
2.1이 나왔네요
그럼 w의 값이 -2.0이면 결과값이 0이 되겠죠.
(왜냐면 아까 위에서 w_re = w + 0.1이었으니까)
w_re = w + 0.1
w_gamso = w + w_re
print(w_gamso)
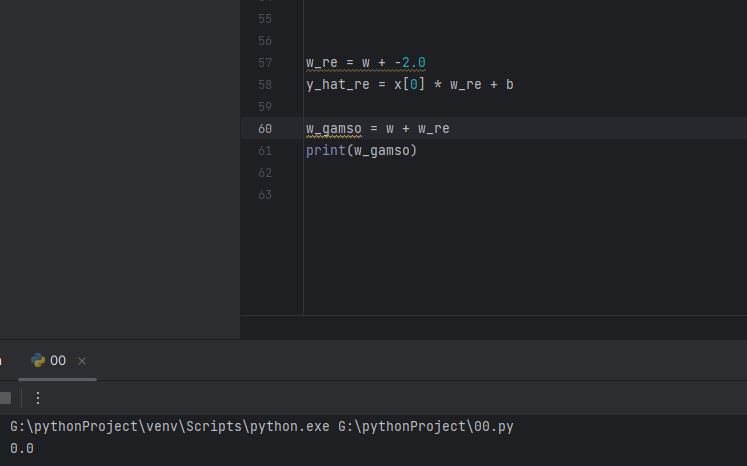
또는 위에 작성한 w_re = w + 0.1를 지우고
-2.0을 적용해줘도 되겠지요
본인이 보기 편하게 하면됨!
w_re = w + -2.0
y_hat_re = x[0] * w_re + b
w_gamso = w + w_re
print(w_gamso)

2. b를 조정하여 증가값 찾기
이번에는 b를 이용해서 증가값을 찾는 방법!
b_re = b + 0.1
y_hat_re = x[0] * w +b_re
print(y_hat_re)
b를 0.1씩 더하는 식을 하나 만들었습니다.
그리고 얼마나 더하고 빼야 할지 모르겠으니까 위에 증가값 찾기 식도 적용해서 얼마나 증가하는지 봅시다.
b_jungga = (y_hat_re - y_hat) / (b_re - b)
print(b_jungga)

변화율이 1이다?
b가 1이 커지면 y햇도 1이 커지는 값이므로
b를 업데이트하려면 1을 더하면 된다!
b_new = b + 1
print(b_new)
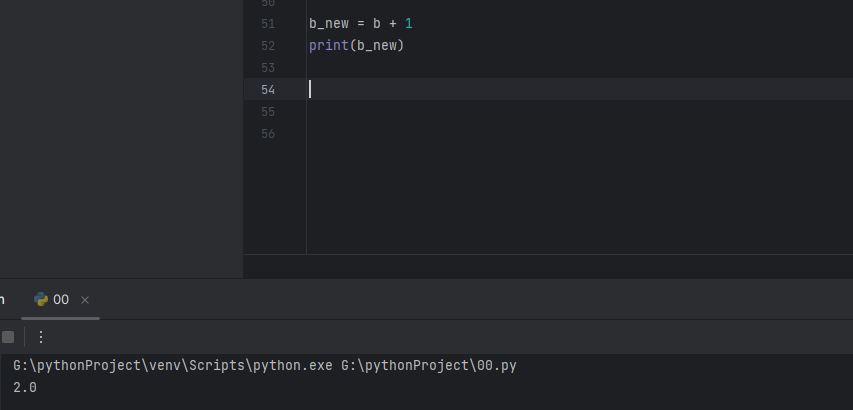
짜란 이 식의 결과는 2.0으로 정직하게 b에 1을 더하면 1이 늘어나는걸 확인 할 수 있었습니다.
우리가 목표한 값은 0이니까 0으로 만들어줍시다.
아까 y햇의 값이 1.2776이었으니 -1.2776을 해주면 되겠네요.
여기까지는 무식하게 w와 b를 업데이트 하는 방법이고
다음시간에는 더 업그레이드 된 방법으로 업데이트 하는 방법을 알려드리도록 하겠습니다.